- Prompt/Deploy
- Posts
- Is My Data Ready?
Is My Data Ready?
An interactive checklist for data readiness. Walk through each data requirement before proceeding with AI development.
Hou C.
February 24, 2026

This post is part of the Mental Models for Production AI series, which explores the mental frameworks needed to evaluate, build, operate, and improve AI-powered features—focusing on practical decision-making.
The previous post made the case for thinking about data before models — four quadrants (Source, Quality, Lineage, Privacy) that set the ceiling for any AI feature.
This post is the checklist. Five questions, in order. Walk through them with your actual data in front of you. The whole thing takes roughly thirty minutes for a first pass — deeper audits take longer.
To keep it concrete, I'll continue with the support ticket classifier from the previous posts — the one that routes incoming tickets to the right team. It passed the "Should We Use AI?" gates. Now the question is whether the data supports building it.
The Tree
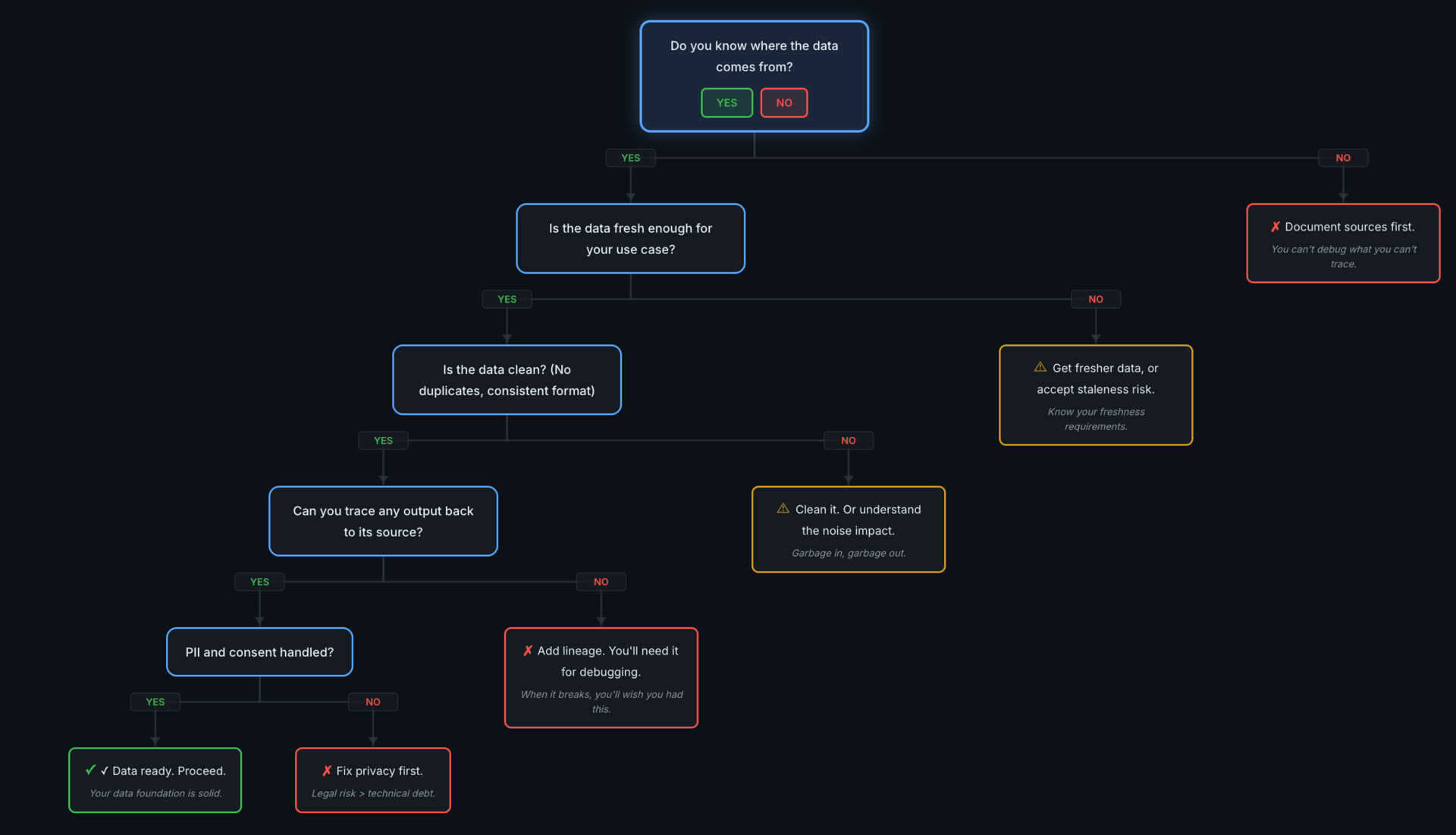
Five checks, two severity levels. Walk them in order.
The flow is sequential: Source → Freshness → Quality → Lineage → Privacy. Two types of outcomes when the answer is "no":
Red (✗ Stop): These are blockers — fix them before proceeding.
Yellow (⚠ Warning): These are risks to understand and either mitigate or accept explicitly.
The order matters. Earlier gaps make later checks harder to interpret. If you can't point to where your data comes from, freshness and quality questions don't have meaningful answers.
Check 1: Do You Know Where the Data Comes From?
✗ STOP if No
This is first because everything else depends on it. You can't evaluate freshness if you don't know the source. You can't trace lineage if you can't name the origin.
What I'd check:
Can you name every system that feeds data into this feature?
Is there a documented schema for each source? When was it last verified?
What happens when a source goes down — do you get an alert, or does the feature silently degrade?
Who owns each source? Not "the database" — a person or team you can ask questions.
The NO path
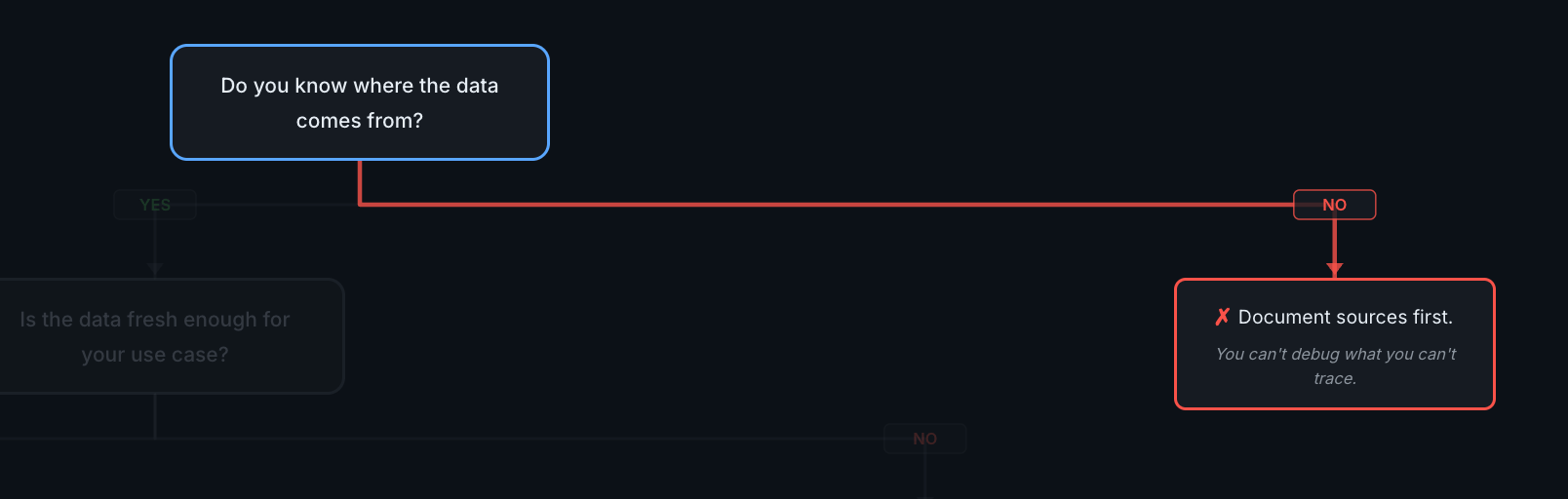
First check fails → stop and document before going further.
Document sources first. You can't debug what you can't trace. The remediation here is straightforward: create a data source inventory. Even a spreadsheet — system name, owner, schema location, update frequency. That's enough to unblock this check.
Running example
The ticket classifier pulls from the Zendesk API (ticket text, metadata) and an internal PostgreSQL database (team assignments, historical routing). Both sources documented, schemas stable, alerting configured for downtime. Check 1: PASS.
ℹ️ Note: The numbers in this running example are illustrative. Swap in your system's actual SLAs, error budgets, and retention requirements.
Check 2: Is the Data Fresh Enough for Your Use Case?
⚠ WARNING if No
The question here is specific: is the staleness budget acceptable for this use case? A nightly sync might be fine for an internal search tool and completely unacceptable for customer-facing pricing.
What I'd check:
Can you query when the data was last updated? If you can't answer this, you can't evaluate freshness at all.
What's the cost of a stale result? An internal routing tool with stale data causes a minor delay. A customer-facing recommendation engine with stale data erodes trust.
If the sync pipeline breaks, how long before someone notices?
Are there downstream consumers who assume a freshness SLA you haven't committed to?
Are you measuring freshness by event time or processing time? A pipeline can run every 15 minutes and still be hours behind if it hits a backlog. Measure lag at the p95/p99 level, not just job frequency.
The NO path
Get fresher data, or accept staleness risk explicitly. This is a warning, not a blocker — some features work fine with daily syncs. The key is making the decision deliberately. Define a staleness budget ("data can be up to 24 hours old for this use case") and
set up monitoring to alert when you exceed it.
Running example
Tickets sync every 15 minutes from Zendesk. For routing purposes, a 15-minute delay is fine — tickets aren't time-critical at the minute level. Staleness budget set at 1 hour, with alerts if the sync pipeline falls behind. Check 2: PASS.
💡 Counter-example: If we were building a real-time escalation system instead of a router, a 15-minute delay could mean a critical ticket sits unescalated. Same data, different use case, different answer on this check.
Check 3: Is the Data Clean?
⚠ WARNING if No
"Clean enough for this use case" — the bar depends on what you're building. As Google's ML Crash Course states, practitioners spend far more time evaluating, cleaning, and transforming data than building models. For classifiers, "clean" goes beyond nulls and duplicates — label consistency and leakage matter just as much, sometimes more. The question is whether you've done enough of that work for the current use case.
What I'd check:
Run a duplicate check. What percentage of records are duplicated?
Check format consistency: are dates in the same format? Are categories spelled the same way?
What's the null rate on critical fields? Nulls in optional fields are fine. Nulls in fields your model depends on are a problem.
If you're building a classifier, check label consistency: do similar records get the same label? Are there confusing pairs (e.g., "billing" vs. "payments")? If multiple people labeled the data, how much do they agree?
Check for leakage: are any fields only available after the decision you're trying to predict? Agent notes, resolution codes, "resolved by" fields — these wouldn't exist at prediction time and will inflate offline metrics.
Sample 50 records manually. Do they look right? Does anything surprise you?
Check for representation bias: are all categories equally represented, or is the data skewed toward certain segments? Bias shows up in both data and evaluation — it often looks like "correct" data until you break metrics out by segment.
The NO path
Clean it, or understand the noise impact. Another warning — dirty data doesn't always block you, but you need to quantify it. Run a basic quality profile: null rates, duplicate rates, format consistency. Then decide what's acceptable. Research on data quality
in ML suggests that performance tends to degrade gracefully until a threshold — then drops sharply. Knowing where you stand relative to that cliff matters.
Running example
Quick audit of 50,000 historical tickets: ~5% have ambiguous category labels (e.g., "billing" vs. "payments"), less than 1% duplicates, formatting is consistent. The 5% noise is within tolerance for a routing classifier — it'll affect the accuracy ceiling but
won't invalidate the approach. Note: clean up ambiguous labels before training. Check 3: PASS (with a remediation note).
Check 4: Can You Trace Any Output Back to Its Source?
✗ STOP if No
If the model gives a wrong answer next week, can you figure out why? Ideally quickly — minutes to hours, depending on your telemetry maturity. Without lineage, debugging often becomes guesswork. You'll spend days tweaking prompts or retrieval parameters
before discovering the problem is upstream in the data.
What I'd check:
If the model produces a wrong output, can you identify which data it used to get there?
Can you version your datasets? If a data update degrades quality, can you roll back?
Are transformations documented — not "we clean the data" but "we remove HTML tags, deduplicate on ticket ID, and normalize categories using this mapping"?
Do dev, staging, and prod use the same data snapshot? If not, you're very likely to hit production issues that don't reproduce locally.
For LLM or RAG features: can you capture the full inference trace — which model version, prompt template, retrieved documents, and tool calls produced a given output? Training-data lineage alone won't help you debug retrieval or prompt failures.
The NO path
Add lineage. You'll need it for debugging — when something breaks, you'll wish you had this. Start with lightweight lineage: record enough metadata to trace outputs back to their inputs and the transformations applied. In practice, that usually means source record IDs, transformation steps, and dataset version identifiers. Even a metadata table is better than nothing. For LLM/RAG systems, extend this to the inference path: log model version, prompt template hash, retrieved document IDs, and any tool calls. You can build sophistication later; what matters now is the ability to trace an output back to its inputs.
Running example
Tickets are versioned by export date. The transformation pipeline logs each step — dedup count, category normalization mapping, field selection. Any training example can be traced back to its original Zendesk ticket ID. Dev and staging use the same snapshot,
refreshed weekly. Check 4: PASS.
Check 5: PII and Consent Handled?
✗ STOP if No
This is the check that carries legal weight. Privacy and consent are legal constraints, not technical preferences. Regulatory fines for data mishandling are real and growing, and erasing specific data from a deployed model can require retraining or specialized unlearning approaches. This check makes the constraint concrete.
What I'd check:
Does the data contain PII? Names, emails, phone numbers, IP addresses — scan for it, don't assume.
If yes, do you have consent to use it for AI/ML purposes? Consent for "providing support" doesn't automatically extend to "training a classifier."
Are retention policies defined and enforced? Deletion has to cover derived datasets, feature stores, logs, and backups — not just the primary source. Can you actually delete data across all copies when required?
If a regulator asked "show me your data handling for this AI feature" today — could you answer?
The NO path
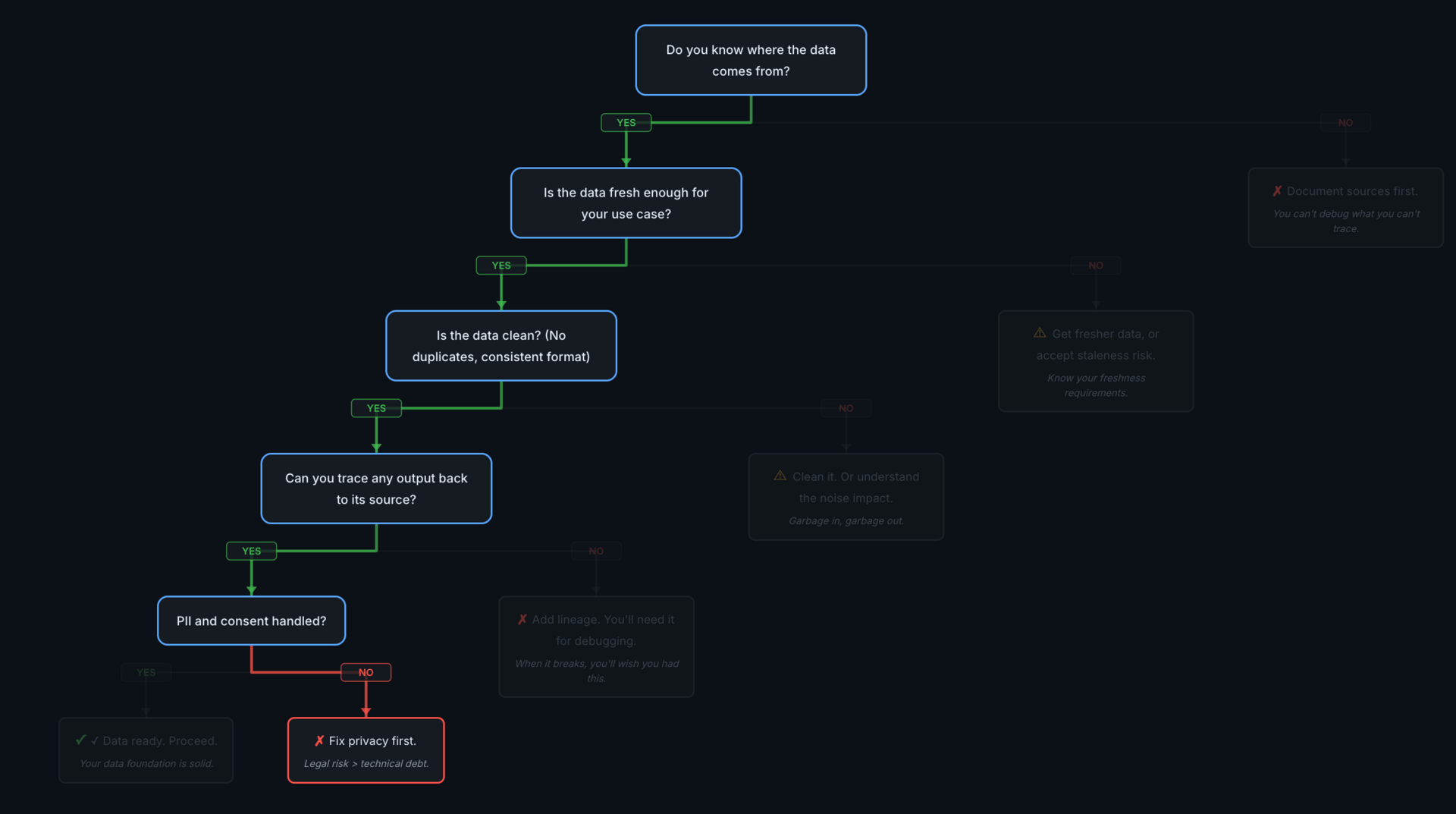
Everything else passes, but a privacy gap is still a stop.
Fix privacy first. Legal risk outweighs technical debt. This is the hardest stop to reverse — a privacy violation after launch is significantly more expensive than building privacy controls in from the start. Run a PII scan on your dataset — but remember scanning is probabilistic, so validate with sampling and maintain a deny-list for known patterns. Document your consent basis, define retention policies, implement access controls. The previous post in this series covers the full privacy landscape — fines, breach patterns, and engineering mitigations.
Running example
Tickets contain customer names and email addresses. PII scan implemented — names and emails redacted before training data is generated. Consent basis documented (legitimate interest for service improvement, reviewed by legal). Retention policy: training data deleted after 12 months. Check 5: PASS.
Reading Your Results
The ticket classifier passed all five checks. Here's what that looks like:
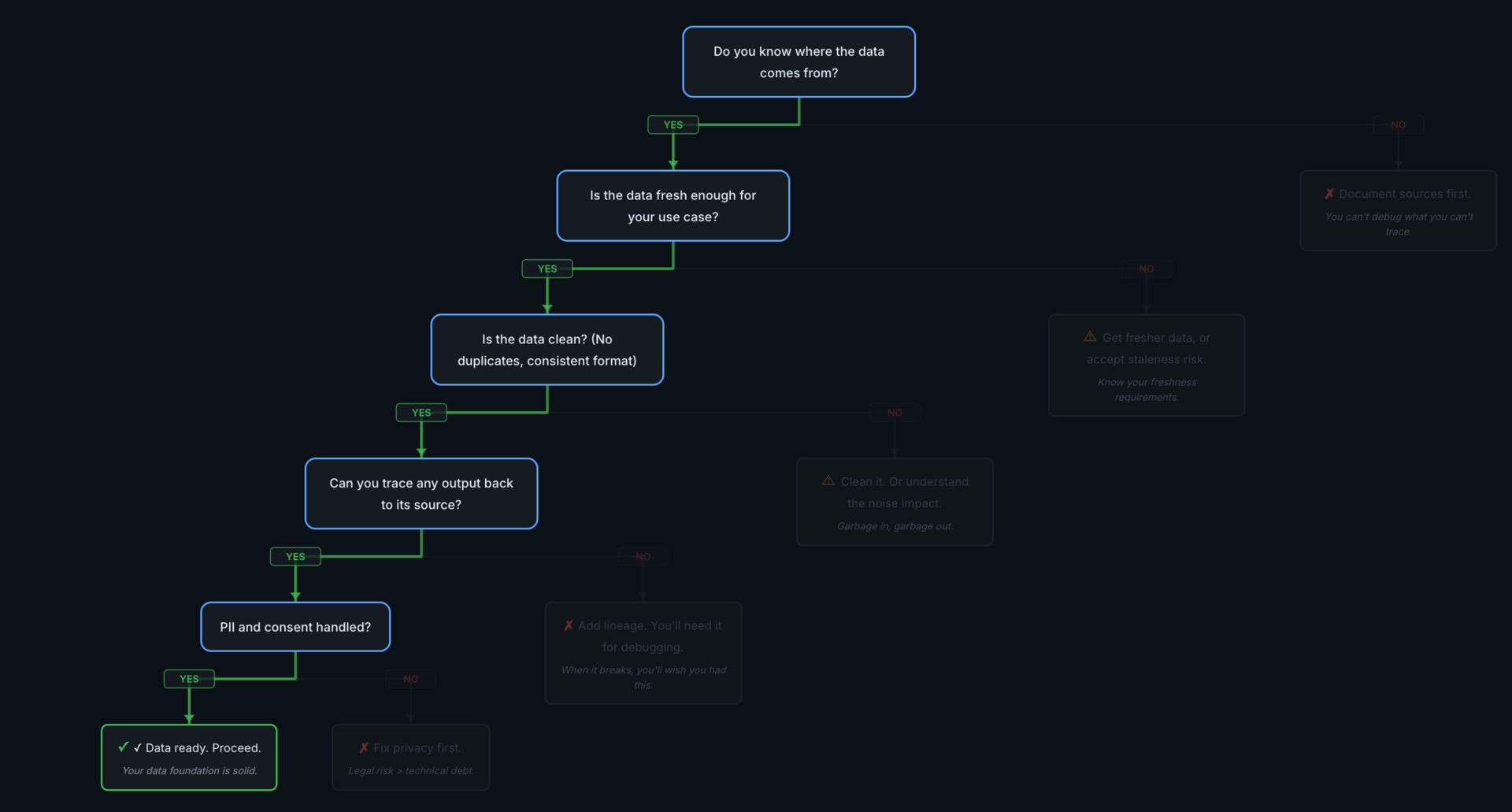
All green — data foundation is solid.
Result | Meaning | Action |
|---|---|---|
All green ✓ | Data foundation is solid | Proceed to architecture decisions |
Any red ✗ | Blocker found | Stop and fix before proceeding |
Yellow ⚠ only | Risks identified | Your call — document the decision |
Yellow warnings don't block you, but they require a deliberate decision. "We know the data is 24 hours stale and we've decided that's acceptable for this use case" is a responsible choice. Discovering the staleness in production because nobody checked is not.
Check 1 (source documentation) and Check 4 (lineage) are common blockers. Checks 2 (Is the Data Fresh Enough for Your Use Case?) and 3 (Is the Data Clean?) usually surface warnings rather than stops — most teams have some data, it's just stale or noisy. The privacy check depends heavily on whether PII is involved at all.
And the tree is repeatable — in both directions. Data that fails today might pass next month. But data that passes today can drift: schemas change, label distributions shift, new PII surfaces. I'd want to re-run these checks on a cadence (quarterly is a
reasonable starting point) and set up alerts for the measurable ones — freshness lag, null rates, label distribution skew. Conditions change. Come back when they do.
What's Next
The ticket classifier's data foundation is solid. The next decisions are architectural: given data that's ready, how should this feature access and use it? That's where the series goes next. The next post covers the RAG vs. fine-tuning decision — when to
retrieve knowledge at query time vs. baking it into the model.
Further Reading
Why I Think About Data Before Models — The conceptual foundation for this checklist
Data Preparation | Google ML Crash Course — Google's guide to evaluating and preparing data for ML
Data Lineage in Machine Learning | Neptune.ai — Practical lineage implementation approaches
Reply