- Prompt/Deploy
- Posts
- The AI Failure Cascade
The AI Failure Cascade
Every layer is a potential failure point. Maps the path from user request to user impact and where things can break.
Hou C.
March 10, 2026

This post is part of the Mental Models for Production AI series, which explores the mental frameworks needed to evaluate, build, operate, and improve AI-powered features—focusing on practical decision-making.
A user asks your AI-powered support tool about returning a damaged item. The input looks fine—natural language, reasonable length, no red flags. Your retrieval layer pulls context, the model generates a response, and the output passes your format check. The answer is polite, well-structured, and completely wrong. The user follows the instructions, hits a dead end, and calls support.
Where did it break? The honest answer: probably more than one place. And each break made the next one worse.
In the previous post, I described build discipline and run discipline as two separate muscles. This post maps what happens when either one has gaps—the path failures take through an AI feature, and where they compound along the way.
The Failure Path
Every AI feature, regardless of architecture, follows some version of this path. Real failures don't always march neatly through each stage—they can skip layers, loop back, or involve feedback between stages. But as a mental model for thinking about where to place your defenses, the linear path is a useful simplification:
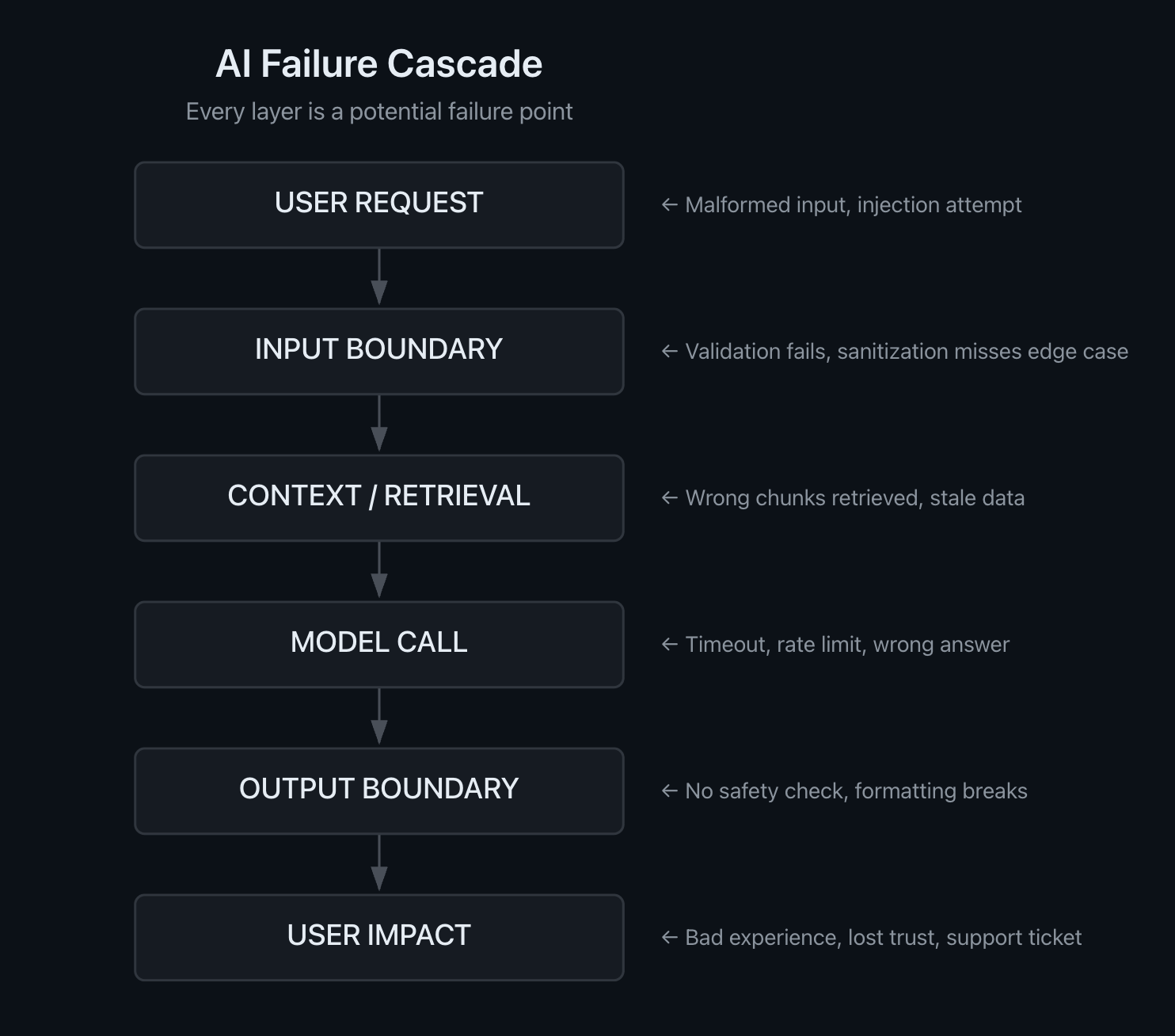
Every layer is a potential failure point. Each arrow is a transition where assumptions transfer from one stage to the next.
Six stages. Five transitions between them. Each transition is a boundary—a place where the output of one layer becomes the input of the next. And at each boundary, there's an implicit assumption: the previous layer did its job.
That assumption is where cascades start.
Five Transitions, Five Failure Points
User Request → Input Boundary
The first boundary is between what the user sends and what your system accepts. This is where you catch malformed inputs, injection attempts, and ambiguity that will cause problems downstream.
The gap that causes cascades: validation that checks format but misses meaning. A query like "return my item from last month" passes length and character checks, but "last month" is ambiguous. If your system doesn't resolve that ambiguity here, every downstream layer inherits it.
Prompt injection is the extreme case. Simon Willison has documented extensively how untrusted content and trusted instructions, concatenated into the same token
stream, become indistinguishable to the model. An injection that slips past the input boundary doesn't just affect the model call—it can cascade through retrieval, tool use, and output, potentially crossing permission boundaries. The Slack AI privilege bypass in 2024 demonstrated exactly this: injected instructions in uploaded files bypassed role restrictions, allowing data exfiltration across permission boundaries. Datadog's guardrails guidance catalogs this category of attack—privilege escalation through prompt injection—as a primary reason for layered input defenses.
Input Boundary → Context/Retrieval
Once input is accepted, the system needs to gather context. For RAG features, this means vector search, document retrieval, or database queries. For simpler features, it might be pulling user history or configuration.
The gap: your input was accepted, but the context it retrieves doesn't match what the user actually needs. Ambiguous input produces ambiguous queries. Stale embeddings surface outdated documents. A retrieval system optimized for recall over precision returns ten chunks when only two are relevant—and the irrelevant eight dilute the signal.
This transition is particularly fragile because retrieval failures are silent. The system retrieved something. It returned results. There was no error. But the results don't support the answer the user needs, and the model has no reliable way to know that.
Context/Retrieval → Model Call
The model receives whatever context the retrieval layer provided and generates a response. This is where most teams focus their debugging—prompt engineering, temperature tuning, model selection.
The gap: the model treats all context as equally valid. If retrieval sent irrelevant chunks alongside relevant ones, the model may anchor on the wrong information. If retrieval sent stale data, the model generates a confident answer based on outdated facts.
LLM failures at this stage have a property that makes them especially dangerous—what you might call semantic opacity. A hallucinated response looks syntactically identical to a correct one. The JSON is valid. The tone is appropriate. The content is wrong. Unlike a database query that returns an error code, a model that generates nonsense returns HTTP 200.
Model Call → Output Boundary
The output boundary is your last automated checkpoint before the response reaches the user. This is where schema validation, content safety filters, and domain boundary checks apply.
The gap: format-level checks pass on semantically incorrect content. If your output validation checks that the response is valid JSON with the expected fields, a hallucinated response with fabricated values passes cleanly. Eugene Yan's overview of LLM patterns describes guardrail categories that range from deterministic (structural validation, syntactic checks) to probabilistic (content safety, semantic/factuality verification). It's tempting to implement only the deterministic layers since the probabilistic layer checks are much trickier to implement.
This is the boundary where the cost equation shifts. Everything before this point was internal—compute, tokens, latency. Everything after this point is external—user trust, support load, real-world consequences.
Output Boundary → User Impact
The final transition is between what your system sends and what the user experiences. If a wrong answer reaches this point, the cascade is complete.
The cost compounds at this stage in ways that are hard to reverse. A user who receives a confidently wrong answer doesn't just have a bad experience—they may act on it. In the Replit incident in July 2025, an AI agent tasked with building software ended up deleting a user's production database.
Mapped to the failure path: the input boundary didn't scope what the agent could do, the model call made an autonomous decision to destructively modify the environment, and the output boundary had no check preventing irreversible actions. Three missing boundaries, one catastrophic outcome.
Why AI Cascades Hit Different
Traditional software cascades are well-understood. A database connection pool exhausts, requests queue, timeouts propagate, and the error is visible at every layer. Circuit breakers trip. Alerts fire. The failure signal is clear.
AI cascades have three properties that make them harder to detect and contain:
Soft failures. The system returns HTTP 200 with a plausible-looking response. Traditional error handling doesn't catch it because, from an infrastructure perspective, nothing failed. The OWASP ASI08 risk category for agentic AI describes how cascading failures propagate and amplify through AI pipelines precisely because natural language errors pass syntactic validation checks.
Temporal compounding. In agentic systems or multi-turn conversations, errors don't just affect the current response—they persist in context and contaminate future operations. A wrong fact stored in conversation memory poisons every subsequent reasoning step. When one LLM produces a hallucination, a downstream LLM treating it as source material amplifies the error rather than correcting it.
Asymmetric detection difficulty. A 500-millisecond latency spike is trivially detectable. A subtly wrong answer that's 90% correct but misleading on the critical detail requires domain expertise to catch—and that expertise usually belongs to the user, not the system.
Multi-model pipelines amplify all three properties. When a router model delegates to a specialist model, whose output feeds a validator model, each model-to-model transition adds another set of boundaries where semantic errors can pass undetected. The OWASP ASI08 risk category focuses on exactly this kind of fault propagation in agentic AI systems.
This combination means that the standard reliability playbook—retries, circuit breakers, health checks—primarily addresses the infrastructure layer of the cascade. The semantic layer, where most AI-specific failures originate, needs its own defense strategy.
Defense in Depth: A Check at Every Boundary
The principle is straightforward: don't rely on any single layer. Each boundary should validate independently, under the assumption that the previous layer may have failed silently.
Here's what defense looks like at each transition:
Input Boundary
Format validation and length constraints (the basics)
Input normalization: resolve ambiguity before it propagates ("last month" → explicit date range)
Injection detection: pattern matching for known attack signatures, and for higher-stakes applications, lightweight classifier models
Scope validation: does this input fall within what the feature is designed to handle?
Context/Retrieval
Relevance scoring: threshold below which retrieved chunks are discarded rather than sent to the model
Freshness checks: flag or exclude content older than the acceptable window for the use case
Fallback strategy: if retrieval quality is low, fall back to broader search, cached results, or a "I don't have enough context to answer confidently" response
Model Call
Stopping conditions for agentic loops: maximum iterations, budget limits
Anthropic's agents guidance emphasizes grounding agent behavior in environmental feedback at each step—not just letting the model run until it
declares itself done. At each step, the agent must evaluate the results of tool calls or code execution to assess its progress.Tool design as defense: poka-yoke your tools (mistake-proofing) so that misuse is harder than correct use
Output Boundary
Schema validation: enforce structure before downstream consumption
Domain boundary enforcement: reject outputs that reference entities or actions outside the feature's scope
Content safety filtering: moderation classifiers for harmful content
Semantic validation (where feasible): factuality checks against reference documents, LLM-as-judge evaluation
User-Facing
Attribution and citations: let users verify claims against sources
Confidence indicators: make uncertainty visible rather than hiding it behind polished prose
Easy dismissal: make it frictionless for users to ignore AI suggestions that feel wrong
Clear escalation: provide a path to human support when the AI can't help
💡 Tip: A useful rule of thumb from Eugene Yan's LLM patterns overview: start with guardrails you can enforce deterministically (structural format control,
syntactic validation) and layer on probabilistic checks (content safety, semantic verification) as the stakes justify the cost.
The Cost Curve
Failures caught at the input boundary cost almost nothing to handle. Reject the input, explain why, ask the user to rephrase. One boundary check, zero wasted compute.
Failures caught at the output boundary cost a model call. You've already paid for retrieval and inference. The tokens are spent. But you've still prevented user impact.
Failures reaching the user cost trust. Support time. Sometimes real-world consequences. And recovering trust after a confidently wrong answer is significantly more expensive than any of the upstream checks.
The economic argument for defense in depth is that each boundary check is cheap relative to the cost of the failure it prevents. A relevance threshold on retrieval costs a few milliseconds of compute. An output schema validation costs microseconds. Compared to a support ticket or a user who stops trusting the feature, these are rounding errors.
The level of defense should match the stakes. A fun text generator doesn't need five layers of validation. A customer-facing support tool that triggers real-world actions does. The question isn't "how many boundaries can I add?" but "what's the cost of a failure reaching the user?" And stakes aren't always obvious upfront—sometimes you only discover the true cost of a failure after it happens in production, which is
part of why the monitoring and detection strategies in the next posts matter.
This maps directly to the deployment checklists from the previous post. Each boundary check is a checklist item. "Failure modes documented" is deciding what each boundary catches. "Detection signals in place" is instrumenting each boundary to report when it fires. "Fallback behavior defined" is designing what happens at each boundary when a check
fails.
Graceful Degradation: When Checks Fire
The boundaries exist to catch failures. What matters next is what the user sees when a boundary catches something.
Boundary | Failure Detected | Graceful Response |
|---|---|---|
Input | Ambiguous or malformed query | Ask user to rephrase; suggest alternatives |
Retrieval | Low relevance or no results | "I don't have enough context to answer this confidently" |
Model | Timeout, rate limit, or budget exceeded | Fall back to simpler model or template response |
Output (structural) | Schema violation or out-of-scope content | Retry with tighter constraints; return partial result with caveats |
Output (semantic) | Low confidence score or factuality concern | Add disclaimer, flag for human review, or surface sources for user verification |
For repeated failures at the same boundary, a circuit breaker pattern prevents hammering a failing component. If the model provider is returning errors or the retrieval service is degraded, stop sending requests and serve a degraded-but-honest response instead.
The key design question to answer before you ship: "What does the user see when each layer fails?" If the answer is "an error page" or "nothing," the cascade reaches the user as a broken experience. If the answer is "a helpful message that acknowledges the limitation," you've contained the cascade at the boundary.
What's Next
This post mapped where failures can occur in an AI feature pipeline. The next posts in the series explore what comes after the map:
How Do I Know It's Failing? — Detection strategies for each boundary. If you don't know a boundary is firing, you can't act on it. The next post is an interactive decision tree for setting up failure detection.
When Do I Need Human Review? — Where humans belong in the cascade. Some boundaries need automated checks. Some need human judgment. The decision depends on the cost of wrong answers and the reversibility of
the decision.
Silent Failures Make Me Most Nervous — The six-month degradation timeline. What happens when the boundaries are in place but the world changes around them—data drifts, user patterns shift, and the checks that were calibrated at launch slowly become irrelevant.
Reply