- Prompt/Deploy
- Posts
- When Should I Retrain or Tune?
When Should I Retrain or Tune?
The decision framework for updates. An interactive guide to knowing when to tune prompts vs retrain models vs investigate deeper.
Hou C.
March 26, 2026

This post is part of the Mental Models for Production AI series, which explores the mental frameworks needed to evaluate, build, operate, and improve AI-powered features—focusing on practical decision-making.
In the previous post, we looked at the Learn layer: how to detect when your AI system is drifting, and what feedback loops keep it healthy. That post ends with a question the monitoring layer can't answer for you: once you know quality is degrading, what do you actually do about it?
The instinct is to say "we need to retrain the model." It feels like the most thorough fix. It's also usually wrong — and acting on it before exhausting cheaper options will cost you weeks.
Here's a decision tree to diagnose what you actually need.
Why This Decision Is Harder Than It Looks
Most production AI quality problems have the same surface symptom: outputs that used to be good are now worse. That symptom has many possible causes:
The retrieval layer is returning noisier results
The prompt has accumulated edge-case patches until it broke
New types of user inputs aren't covered by the model's training distribution
The definition of "correct" has shifted — your ground truth changed
Each of these requires a different fix. The mistake is reaching for the most expensive fix (retraining) before ruling out the cheaper ones (prompt tuning, retrieval fixes, data
augmentation). OpenAI's model optimization guidance recommends starting with evals and prompt engineering before escalating to fine-tuning. Retraining from scratch is rarely mentioned because it's rarely the answer for a single degrading use case.
The decision tree below makes that hierarchy concrete. Five gates, evaluated in order. Each gate either resolves the problem or hands off to the next.
What This Tree Covers
This tree assumes you have a deployed AI feature that was working and is now underperforming. It's not a guide for building from scratch.
A few scoping notes:
This tree applies whether you're calling a hosted API or managing your own model weights. The diagnostic gates are the same — what changes is the set of interventions available at each exit. Gates 4 and 5 call out where the paths diverge.
"Retrain" in this tree means updating model weights. That covers fine-tuning (adjusting existing weights for a specific task) and full retraining (rebuilding from scratch or continued pre-training on a new corpus). Gates 4 and 5 handle the distinction between them.
This tree doesn't replace evals. The first gate is specifically about whether you have the measurement infrastructure to make any of the subsequent decisions. If you don't, this tree can't help you.
Passing all gates toward fine-tuning doesn't mean you must fine-tune. It means model-level intervention is likely warranted. Context matters: if you're using a hosted model API, fine-tuning may mean adjusting your calls, few-shot examples, or requesting a model version pin — not training weights yourself.
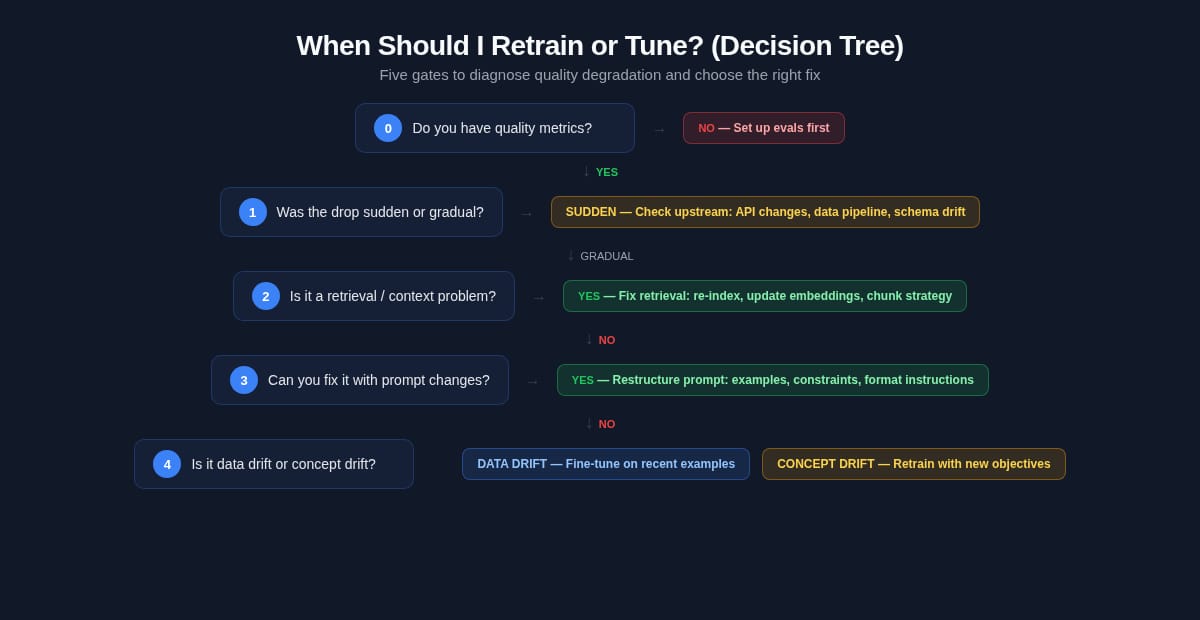
The full decision tree. Most paths exit before reaching model-weight updates. Fine-tuning and retraining are gates 4 and 5.
How to Read This Tree
Five gates, evaluated in order. Each gate either:
Exits with a specific action (fix the retrieval pipeline, restructure the prompt)
Continues to the next gate (rules out this cause, escalates to deeper diagnosis)
Every "exit" is a concrete action. Landing at "fix your prompt" isn't a dead end — the note for that gate explains what to actually do.
Escalate only with evidence. Don't skip gates because they feel too simple. The most common error is assuming the model is the problem when a retrieval fix would take an afternoon.
To make this concrete, I'll use a running example: a customer support classifier that routes incoming tickets to the right team. It was working well at launch; six months later, routing accuracy has dropped and user complaints are up.
Gate 0: Do You Have Quality Metrics?
The decision tree starts here. Every gate after this one requires measurable signals to navigate. Without them, you're guessing — and the guess is usually "retrain."
What YES looks like
A task-specific evaluation set: 20+ labeled examples with ground truth answers, a consistent scoring method (automated eval, LLM-as-judge, or human review), and a baseline reading from when the system was working well. You can compare current performance against that baseline. If you don't have this yet, that's normal — most teams don't start with evals in place. The NO path below tells you exactly where to begin.
For the ticket classifier: "Route tickets to the correct team with >85% accuracy, measured against a human-labeled test set of 500 tickets. Baseline accuracy at launch was 91%. Current: 74%."
That's enough to navigate the rest of the tree.
What NO looks like
You know quality is down because users are complaining or someone eyeballed recent outputs. But there's no metric, no baseline, no eval set.
The NO path
Build evals first. Read Post 13 for the monitoring layer — specifically the section on setting up feedback signals and evaluation cadences. Come back to this tree once you have a baseline and a current reading you can compare.
This isn't a detour. Diagnosing without metrics leads to expensive interventions that may not fix the actual problem.
Running example
We have metrics (74% vs 91% baseline). Gate 0: PASS.
Gate 1: Is the Degradation Gradual or a Sudden Drop?
Two very different patterns present as "quality went down," but they point to different causes.
Sudden drop
A sharp decline in a short window usually traces to a system change, not model drift. Check:
Did the prompt change recently?
Did the model version change? (Some APIs update the underlying model behind a stable endpoint name)
Did the retrieval corpus or database change?
Did traffic patterns shift dramatically (new user segment, spike in a specific query type)?
If any of these correlate with the drop, you're looking at a regression from a specific change — not model degradation. Roll back or fix the change. No model update needed.
⚠️ Watch for this: Providers sometimes update model versions behind stable-sounding endpoint names. If your call is hitting gpt-4 and not a pinned version like gpt-4-0613, the model may have changed without your code changing. Check provider changelogs before assuming the model is the same one it was six months ago.
Gradual decline
A slow degradation over weeks or months without a clear system change event is the pattern this tree is built for. Continue to Gate 2.
Running example
Our ticket classifier accuracy has been trending down for three months, no major system changes. Gate 1: gradual decline → continue.
Gate 2: Is the Right Context Getting to the Model?
Before touching model weights, rule out the retrieval and context layer. This gate catches the most commonly misdiagnosed "model problems."
The retrieval test
Run your failing examples with manually-crafted perfect context injected directly — bypassing your retrieval pipeline. Does quality recover?
Failing example (automated retrieval):
Input: "I can't log in after changing my password"
Retrieved context: [docs about billing, account plans] ← wrong chunk
Output: "Looks like a billing issue" ← wrong category
Same example (manual context injection):
Input: "I can't log in after changing my password"
Injected context: [docs about auth, login troubleshooting] ← correct
Output: "Authentication issue — routing to auth team" ← correct
If outputs improve dramatically with manually injected context: the model is fine. The retriever is broken. Common culprits: embedding model mismatch with the corpus, chunk sizes that split important context, retrieval returning too many results and triggering "lost in the middle" failure, or incorrect metadata filtering.
Other context-layer failures to check
Context window overflow: Is the model receiving more tokens than it can reliably attend to? Information buried late in a very long context is often ignored: the model's attention degrades for tokens far from the retrieval window, regardless of whether the answer is technically present.
Context formatting errors: Are retrieved results being injected in a format the model can parse? Malformed JSON, broken XML structure, or inconsistent delimiter patterns can cause failures that look like model confusion.
The NO path
If quality doesn't recover with manual context injection, the problem isn't retrieval. Continue to Gate 3.
The YES path
Fix the retrieval pipeline. No model update needed. The ticket classifier example might resolve here if the retrieval index was last rebuilt when ticket categories were different.
Running example
Running the test: manual context injection partially improves results, but 12% accuracy gap remains after retrieval is fixed. Gate 2: retrieval is a partial contributor, not the full cause → fix retrieval, continue with adjusted baseline.
Gate 3: Is This Prompt-Fixable?
Prompt engineering handles more than people expect before reaching for model-weight updates — though "more than people expect" isn't "everything." If you've already spent serious effort on prompt restructuring and the gap persists, that's exactly what this gate is designed to detect. Both Anthropic and OpenAI recommend trying prompt engineering before fine-tuning. The general guidance from both providers: prompt-level improvements are faster to iterate on and often sufficient for tasks where the model already has the underlying capability.
Signs it's a prompt problem
Outputs are inconsistent: the model sometimes follows instructions and sometimes doesn't
New edge cases aren't covered: a category of inputs that didn't exist at launch is now failing
Output format issues: the model drifts from the expected schema or structure
Tone or style regression: behavior that few-shot examples used to reliably shape is now inconsistent
The prompt-first test
Add 3-5 explicit few-shot examples for your failing cases to the prompt. Include examples that specifically demonstrate the correct behavior for the patterns you're seeing fail. Does quality recover?
For the ticket classifier: add explicit examples showing how to classify "API integration questions" (a new category that emerged after launch) with the correct routing. If accuracy recovers: no fine-tuning needed.
What prompt tuning cannot fix
Missing knowledge: If the model lacks domain facts entirely, prompt engineering can't supply them (RAG can)
Deep behavioral drift at scale: If the failure pattern is widespread and varied, prompt patching treats symptoms. Gate 4 handles this.
Outdated factual associations: If the model's learned associations are simply wrong for your current use case, adding examples to the prompt has limited leverage
The NO path
If prompt restructuring and few-shot examples don't meaningfully improve quality on your failing cases: continue to Gate 4.
The YES path
Restructure the prompt, add few-shot examples, clarify the system message. No model update needed.
Running example
We add explicit examples for new ticket categories. Accuracy recovers to 83% — close to baseline but with a persistent 8% gap on a specific failure pattern. Gate 3: partially fixable → fix what prompts can, continue investigating remaining gap.
Gate 4: What Kind of Drift Are You Seeing?
If you've reached this gate, you've confirmed: metrics are degrading gradually, context isn't the full explanation, and prompt tuning hasn't closed the gap. There's a model-level issue. The question now is what kind of drift — because the fix is different.
Data drift vs concept drift
This distinction is the most commonly confused in production AI diagnosis:
Data drift | Concept drift | |
|---|---|---|
What changed | The input distribution — new types of inputs the model wasn't trained on | The correct answer — what counts as right has changed, even for familiar inputs |
What it looks like | Failures concentrated in new input patterns; familiar inputs still work | Failures across familiar inputs too; the model's predictions were right before, now wrong |
How to detect | New input clusters in your logs; high error rate on unfamiliar query types | Degradation on historically well-performing examples; ground truth labels have shifted |
Fix | Add training examples covering new input types; fine-tuning on new examples is often sufficient | Retraining may be needed; the learned associations are now actively wrong |
Concrete examples
Data drift — ticket classifier: Your support bot was trained when your product had three teams: billing, technical, and general. After a product expansion, customers are now asking about API integration and enterprise contracts — categories that simply didn't exist at training time. The model isn't "wrong" about how to classify billing tickets. It just hasn't seen these new patterns.
Fix: collect labeled examples of the new categories, fine-tune on them. The model's existing weights are mostly correct — you're extending coverage, not correcting errors.
Concept drift — ticket classifier: Your company changed its escalation policy: security questions that used to go to "technical" now go to a dedicated "security" team. Same input, different correct answer. The model will confidently route security questions to technical — because that was correct when it was trained.
Fix: this requires retraining on the updated labeling scheme because the relationship between inputs and correct outputs has changed. Prompt engineering or few-shot examples can partially compensate, but if there are many such policy changes, the model's learned associations are a liability.
Diagnostic
Look at your failing examples. Are they:
Concentrated in new input types? → Likely data drift
Spread across familiar inputs with previously correct outputs now wrong? → Likely concept drift
Running example
Our classifier's remaining failures are concentrated on a new ticket category (API integration), not on historically correct ones. Gate 4: data drift → fine-tuning on new examples is the likely fix.
Gate 5: Fine-Tune or Full Retrain?
If you've confirmed drift requires a model-level update, the question is whether to fine-tune (adjust existing weights) or fully retrain (rebuild from scratch or continue pre-training on a new corpus).
In practice, for almost every individual use case that has reached this gate, fine-tuning is the right intervention.
When fine-tuning is appropriate
Fine-tuning adjusts existing weights for new task patterns. It preserves the model's broad capabilities while adapting behavior for your specific domain. It's the right tool when:
You need to extend coverage to new input types (data drift scenario)
You need to fix behavioral inconsistency for a specific task
You need the model to internalize patterns that are too numerous or complex for few-shot examples
Estimated data need: 50+ high-quality examples as a starting point — expand based on eval results if quality doesn't improve
💡 Tip: Quality of training data matters more than quantity when fine-tuning on a foundation model. A modest set of carefully labeled, representative examples typically outperforms a much larger noisy dataset. Start small, measure against your eval set, and expand if the gap doesn't close.
Fine-tuning does not fix: missing knowledge at scale (that's RAG territory), or concept drift extensive enough that the model's existing associations are broadly counterproductive.
When full retraining is warranted
Full retraining — rebuilding from scratch or continued pre-training on a large new corpus — is warranted when:
The input distribution has shifted so fundamentally that existing weights are actively counterproductive across many tasks simultaneously
You need to integrate domain-specific knowledge at a scale that retrieval augmentation can't handle
Concept drift has spread across so many categories that fine-tuning individual task patterns isn't practical
For most teams using foundation models via API: full retraining isn't available, and isn't the right mental model anyway. The relevant question is whether the provider's fine-tuning offering (or a model swap to a newer version) resolves the issue, or whether you need to rebuild your own model. The latter is a significant engineering commitment that should be treated as a separate product decision, not a debugging step.
The cost argument
Fine-tuning requires a minimum of 50+ high-quality labeled examples, plus evaluation cycles. Full retraining requires significantly more data, compute, and time. Both require updated evaluation pipelines to verify the fix worked. The cost of each option should weigh in the decision — which is why this gate should only be reached after exhausting Gates 1–4.
Running example
Data drift from a new ticket category → fine-tune on 200+ examples covering API integration and enterprise contract tickets. Evaluate against the existing test set + a new held-out sample for the new categories. Gate 5: fine-tune.
If None of the Above — Deep Debug
Rare, but real: you've been through all five gates and quality is still unaccounted for. A few escalation paths:
Your eval set is stale. If the evaluation examples were labeled months ago, they may no longer represent the failure modes you're seeing in production. Rebuild the eval set before concluding the model is the problem.
The product definition changed. Sometimes quality degradation isn't the model drifting — it's that what users need has evolved. This isn't model degradation; it's feature drift. The fix is a product conversation, not a training run.
Model version pinning. If you're using a hosted model and aren't pinning to a specific version, the provider may have updated the underlying model. Check if version-pinning to the previously working release resolves the issue.
ML specialist territory. If you're seeing concept drift at scale and are managing your own model weights, you've reached the point where continued pre-training strategies —
selectively retraining on a mixed corpus of new and old data — require ML expertise. This is a legitimate escalation, not a failure. The right question to bring: "Here are the specific input categories where our model is now wrong; we need a data strategy for retraining without regressing on categories that still work."
Summary: The Full Decision Path
Five gates, in order:
Do you have quality metrics? → No: build evals first. Yes: continue.
Is the decline gradual or sudden? → Sudden: investigate system changes first. Gradual: continue.
Is the right context reaching the model? → Yes: fix retrieval/context. No: continue.
Is this prompt-fixable? → Yes: restructure prompt, add few-shot examples. No: continue.
What kind of drift? → Data drift: fine-tune on new examples. Concept drift: may require retraining.
The core rule: start with the cheapest intervention that could plausibly fix the problem. Escalate only when you have evidence the cheaper fix wasn't enough.
Retraining is not the default. It's the last resort after cheaper interventions fail — and in most production cases, they don't fail. They just require the patience to test them in order. (The exception: if you already know the model was trained on a narrow or outdated dataset, you may reach Gate 4 quickly. The tree still helps — it confirms the diagnosis before you commit
to the cost.)
This is the final post in the Mental Models for Production AI series. The full loop: decide whether to use AI (Post 1 → understand your data (Posts 4–6) → ship with proper execution (Posts 7–9) → detect failures (Posts 10–12) → build feedback loops (Post 13) → diagnose and fix degradation (this post).
Further Reading
Optimizing LLM Accuracy (OpenAI) — strategies for improving model output quality
Model Optimization Guide (OpenAI) — overview of fine-tuning, reinforcement learning, and best practices
LLM Patterns (Eugene Yan) — production practitioner guidance on fine-tuning decisions
Learning under Concept Drift: A Review (arxiv) — formal treatment of drift taxonomy
Reply